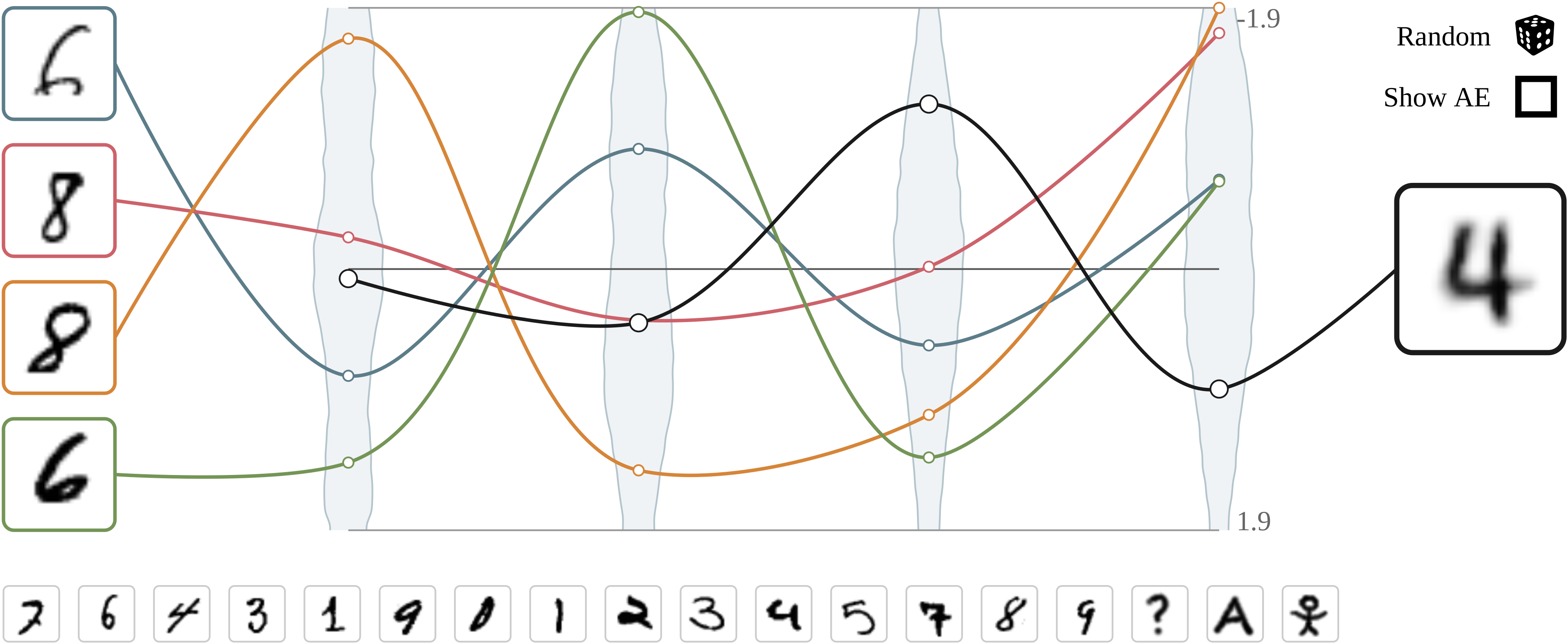
Visualizing activations in latent space of an AE/VAE.
Material
Abstract
We present an intuitive comparison of Auto-Encoders (AE) with Variational Auto-Encoders (VAE) by visualizing their latent activations. In order to do this, we trained an AE and the corresponding VAE on the MNIST dataset. To give a feeling for the latent compression, we visualize the latent activations of the AE/VAE by displaying the 4 latent variables in a parallel coordinate system. We provide an introduction to the architectures of AEs/VAEs and draw a comparison between the two models.