Material
Abstract
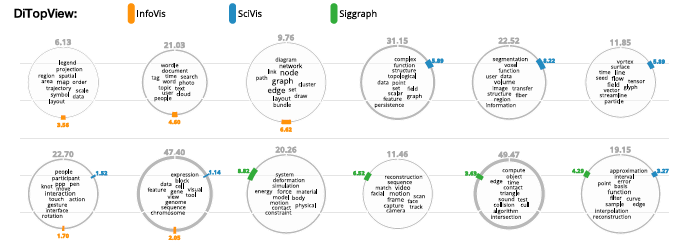
We present an analysis and visualization method for computing what distinguishes a given document collection from others. We determine topics that discriminate a subset of collections from the remaining ones by applying probabilistic topic modeling and subsequently approximating the two relevant criteria distinctiveness and characteristicness algorithmically through a set of heuristics. Furthermore, we suggest a novel visualization method called DiTop-View, in which topics are represented by glyphs (topic coins) that are arranged on a 2D plane. Topic coins are designed to encode all information necessary for performing comparative analyses such as the class membership of a topic, its most probable terms and the discriminative relations. We evaluate our topic analysis using statistical measures and a small user experiment and present an expert case study with researchers from political sciences analyzing two real-world datasets.